
运行:systemctl restart systemd-logind
去芜存菁
运行:systemctl restart systemd-logind
用U盘安装Kali Linux的过程中,出现cd-rom无法挂载的现象
下面亲测成功
出现无法挂载后,选择执行shell
第一步:df -m
此时会看到挂载信息,最下面的是/dev/*** /media 表示U盘设备挂载到了/media,导致cd-rom不能被挂载。
第二步:umount /media
第三步:exit
退出shell窗口,继续安装。此时可正常安装下去。

1.epoll函数会监听注册在自己名下的所有的socket描述符
2.当有socket感兴趣的时间发生时,epoll函数才会相应,并返回有时间发生的socket集合
3.epoll的本质是阻塞IO,他的优点在于能同时处理大量socket连接
在这个epoll进程之内同时处理多个描述符
其实并不是异步的
wrk负载测试时可以运行在一个或者多核CPU,wrk结合了可伸缩的事件通知系统epoll和kqueue等多线程设计思想。目前wrk可以安装在Linux系统和Mac系统,下面看下wrk在Linux下的安装和用法。
1、压力测试工具wrk安装
[root@localhost /]# yum install git #安装git [root@localhost wrk]# git clone https://github.com/wg/wrk.git #复制一份wrk源码文件 [root@localhost wrk]# cd /wrk/ #进入wrk源码文件夹 [root@localhost wrk]# mkdir /wrk #编译wrk [root@localhost wrk]# cp ./wrk /usr/local/bin/ #复制到用户bin目录下
2、压力测试工具wrk用法
[root@localhost wrk]# wrk -t8 -c400 -d30s http://127.0.0.1 Running 30s test @ http://127.0.0.1 8 threads and 400 connections Thread Stats Avg Stdev Max +/- Stdev Latency 96.88ms 75.53ms 1.93s 97.18% Req/Sec 554.79 60.39 680.00 78.48% 131271 requests in 30.05s, 97.40MB read Requests/sec: 4368.91 Transfer/sec: 3.24MB
3、压力测试工具wrk常用参数
-t 线程数
-c HTTP连接数
-d 测试执行时间
我们先来做一个简单的性能测试:
wrk -t12 -c100 -d30s http://www.baidu.com
30秒钟结束以后可以看到如下输出:
Running 30s test @ http://www.baidu.com 12 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 538.64ms 368.66ms 1.99s 77.33% Req/Sec 15.62 10.28 80.00 75.35% 5073 requests in 30.09s, 75.28MB read Socket errors: connect 0, read 5, write 0, timeout 64 Requests/sec: 168.59 Transfer/sec: 2.50MB
先解释一下输出:
12 threads and 100 connections
这个能看懂英文的都知道啥意思: 用12个线程模拟100个连接.
对应的参数 -t 和 -c 可以控制这两个参数.
一般线程数不宜过多.
核数的2到4倍足够了.
多了反而因为线程切换过多造成效率降低.
因为 wrk 不是使用每个连接一个线程的模型, 而是通过异步网络 io 提升并发量.
所以网络通信不会阻塞线程执行.
这也是 wrk 可以用很少的线程模拟大量网路连接的原因.
而现在很多性能工具并没有采用这种方式, 而是采用提高线程数来实现高并发.
所以并发量一旦设的很高, 测试机自身压力就很大.
测试效果反而下降.
下面是线程统计:
Thread Stats Avg Stdev Max +/- Stdev Latency 538.64ms 368.66ms 1.99s 77.33% Req/Sec 15.62 10.28 80.00 75.35%
Latency: 可以理解为响应时间, 有平均值, 标准偏差, 最大值, 正负一个标准差占比.
Req/Sec: 每个线程每秒钟的完成的请求数, 同样有平均值, 标准偏差, 最大值, 正负一个标准差占比.
一般我们来说我们主要关注平均值和最大值. 标准差如果太大说明样本本身离散程度比较高. 有可能系统性能波动很大.
接下来:
5073 requests in 30.09s, 75.28MB read Socket errors: connect 0, read 5, write 0, timeout 64 Requests/sec: 168.59 Transfer/sec: 2.50MB
30秒钟总共完成请求数和读取数据量.
然后是错误统计, 上面的统计可以看到, 5个读错误, 64个超时.
然后是所以线程总共平均每秒钟完成168个请求. 每秒钟读取2.5兆数据量.
可以看到, 相对于专业性能测试工具. wrk 的统计信息是非常简单的. 但是这些信息基本上足够我们判断系统是否有问题了.
wrk 默认超时时间是1秒. 这个有点短. 我一般设置为30秒. 这个看上去合理一点.
如果这样执行命令:
1. /wrk -t12 -c100 -d30s -T30s http://www.baidu.com
可以看到超时数就**降低了, Socket errors 那行没有了:
1. Running 30s test @ http://www.baidu.com
2. 12 threads and 100 connections
3. Thread Stats Avg Stdev Max +/- Stdev
4. Latency 1.16s 1.61s 14.42s 86.52%
5. Req/Sec 22.59 19.31 108.00 70.98%
6. 4534 requests in 30.10s, 67.25MB read
7. Requests/sec: 150.61
8. Transfer/sec: 2.23MB
通过 -d 可以设置测试的持续时间. 一般只要不是太短都是可以的. 看你自己的忍耐程度了.
时间越长样本越准确. 如果想测试系统的持续抗压能力, 采用 loadrunner 这样的专业测试工具会更好一点.
想看看响应时间的分布情况可以加上–latency参数:
1. wrk -t12 -c100 -d30s -T30s –latency http://www.baidu.com
1. Running 30s test @ http://www.baidu.com
2. 12 threads and 100 connections
3. Thread Stats Avg Stdev Max +/- Stdev
4. Latency 1.22s 1.88s 17.59s 89.70%
5. Req/Sec 14.47 9.92 98.00 77.06%
6. Latency Distribution
7. 50% 522.18ms
8. 75% 1.17s
9. 90% 3.22s
10. 99% 8.87s
11. 3887 requests in 30.09s, 57.82MB read
12. Socket errors: connect 0, read 2, write 0, timeout 0
13. Requests/sec: 129.19
14. Transfer/sec: 1.92MB
可以看到50%在0.5秒以内, %75在1.2s 以内. 看上去还不错.
看到这里可能有人会说了, HTTP 请求不会总是这么简单的, 通常我们会有 POST,GET 等多个 method, 会有 Header, 会有 body 等.
在我第一次知道有 wrk 这个工具的时候他确实还不太完善, 要想测试一些复杂的请求还有点难度. 现在 wrk 支持 lua 脚本. 在这个脚本里你可以修改 method, header, body, 可以对 response 做一下自定义的分析. 因为是 lua 脚本, 其实这给了你无限的可能. 但是这样一个强大的功能如果不谨慎使用, 会降低测试端的性能, 测试结果也受到影响.
一般修改method, header, body不会影响测试端性能, 但是操作 request, response 就要格外谨慎了.
我们通过一些测试场景在看看怎么使用 lua 脚本.
POST + header + body.
首先创建一个 post.lua 的文件:
1. wrk.method = "POST"
2. wrk.body = "foo=bar&baz=quux"
3. wrk.headers["Content-Type"] = "application/x-www-form-urlencoded"
就这三行就可以了, 当然 headers 可以加入任意多的内容.
然后执行:
1. wrk -t12 -c100 -d30s -T30s –script=post.lua –latency http://www.baidu.com
当然百度可能不接受这个 post 请求.
对 wrk 对象的修改全局只会执行一次.
通过 wrk 的源代码可以看到 wrk 对象的源代码有如下属性:
1. local wrk = {
2. scheme = "http",
3. host = "localhost",
4. port = nil,
5. method = "GET",
6. path = "/",
7. headers = {},
8. body = nil,
9. thread = nil,
10. }
schema, host, port, path 这些, 我们一般都是通过 wrk 命令行参数来指定.
wrk 提供的几个 lua 的 hook 函数:
setup 函数
这个函数在目标 IP 地址已经解析完, 并且所有 thread 已经生成, 但是还没有开始时被调用. 每个线程执行一次这个函数.
可以通过thread:get(name), thread:set(name, value)设置线程级别的变量.
init 函数
每次请求发送之前被调用.
可以接受 wrk 命令行的额外参数. 通过 — 指定.
delay函数
这个函数返回一个数值, 在这次请求执行完以后延迟多长时间执行下一个请求. 可以对应 thinking time 的场景.
request函数
通过这个函数可以每次请求之前修改本次请求的属性. 返回一个字符串. 这个函数要慎用, 会影响测试端性能.
response函数
每次请求返回以后被调用. 可以根据响应内容做特殊处理, 比如遇到特殊响应停止执行测试, 或输出到控制台等等.
1. function response(status, headers, body)
2. if status ~= 200 then
3. print(body)
4. wrk.thread:stop()
5. end
6. end
done函数
在所有请求执行完以后调用, 一般用于自定义统计结果.
1. done = function(summary, latency, requests)
2. io.write("——————————\n")
3. for _, p in pairs({ 50, 90, 99, 99.999 }) do
4. n = latency:percentile(p)
5. io.write(string.format("%g%%,%d\n", p, n))
6. end
7. end
下面是 wrk 源代码中给出的完整例子:
1. local counter = 1
2. local threads = {}
3.
4. function setup(thread)
5. thread:set("id", counter)
6. table.insert(threads, thread)
7. counter = counter + 1
8. end
9.
10. function init(args)
11. requests = 0
12. responses = 0
13.
14. local msg = "thread %d created"
15. print(msg:format(id))
16. end
17.
18. function request()
19. requests = requests + 1
20. return wrk.request()
21. end
22.
23. function response(status, headers, body)
24. responses = responses + 1
25. end
26.
27. function done(summary, latency, requests)
28. for index, thread in ipairs(threads) do
29. local id = thread:get("id")
30. local requests = thread:get("requests")
31. local responses = thread:get("responses")
32. local msg = "thread %d made %d requests and got %d responses"
33. print(msg:format(id, requests, responses))
34. end
35. end
https://sanwen8.cn/p/1d4kAUJ.html
1、备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2、下载新的CentOS-Base.repo 到/etc/yum.repos.d/
CentOS 5
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-5.repo
CentOS 6
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
CentOS 7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3、生成缓存
yum makecache
http://mirrors.aliyun.com/help/centos
先查看服务器上的 erase 信号的映射:

可以看出这里的 erase 信号为 ^?,而发送过去的却是 ^H,这就是敲击 Backspace 时为什么不会删除字符而会显示 ^H 的原因,如果要解决这个问题,可以使用 Ctrl-Backspace 键来发送 ^? 信号来删除字符,但是这样还是太麻烦了,需要用组合键,而最简单的方法就是把 Linux 服务器中的 erase 信号设置为 ^H:
再看一下 erase 信号的映射:

变为 ^H 了,这样就可以敲击 Backspace 来删除字符,但是这样只是临时的,系统重启过后就会失效,可以把这条命令写入家目录下的 .bash_profile 文件中实现永久修改
后台执行用 nohup + sh + &就可以了
ps aux | grep sh
kill pid就能停止了
linux的终端上,没有windows的搜索那样好用的图形界面工具,但find命令确是很强大的。
比如按名字查找一个文件,可以用 find / -name targetfilename 。 唉,如果只知道名字,不知道地点,这样也不失为一个野蛮有效的方法。
按时间查找也有参数 -atime 访问时间 -ctime 改变状态的时间 -mtime修改的时间。但要注意,这里的时间是以24小时为单位的。查看man手册后使用,你会很迷惑: -mtime n: Files data was last modified n*24 hours ago. 字面上的理解是最后一次修改发生在n个24小时以前的文件,但实际上
find ./ -mtime 0:返回最近24小时内修改过的文件。
find ./ -mtime 1 : 返回的是前48~24小时修改过的文件。而不是48小时以内修改过的文件。
那怎么返回10天内修改过的文件?find还可以支持表达式关系运算,所以可以把最近几天的数据一天天的加起来:
find ./ -mtime 0 -o -mtime 1 -o -mtime 2 ……虽然比较土,但也算是个方法了。
还有没有更好的方法,我也想知道。
另外, -mmin参数-cmin / – amin也是类似的。
wanqi@wanqi-System-Product-Name:~/huiye_QRD_e8/7x27a-11302301$ find ./packages/apps/ -name *.java -mtime 2
./packages/apps/filebrowser2/src/com/android/filebrowser/MyFile.java
./packages/apps/filebrowser2/gen/com/android/filebrowser/Manifest.java
./packages/apps/filebrowser2/gen/com/android/filebrowser/R.java
./packages/apps/Settings/src/com/android/settings/multisimsettings/MultiSimManager2.java
./packages/apps/Settings/src/com/android/settings/multisimsettings/MultiSimUtil.java
./packages/apps/Camera/src/com/android/camera/ListPreference.java
./packages/apps/Camera/src/com/android/camera/ui/PreferenceAdapter.java
wanqi@wanqi-System-Product-Name:~/huiye_QRD_e8/7x27a-11302301$ find ./packages/apps/ -name *.java -mtime 2
./packages/apps/filebrowser2/src/com/android/filebrowser/MyFile.java
./packages/apps/filebrowser2/gen/com/android/filebrowser/Manifest.java
./packages/apps/filebrowser2/gen/com/android/filebrowser/R.java
SecureCRT默认显示效果是黑白且刺眼的主题,看起来很不舒服。经过一番搜索,总结结果如下,直接设置默认属性,设置一次,不需再改。
效果图:

具体操作方法:
Options->Global Options进入下面设置
说明:
④选择Linux配色方案
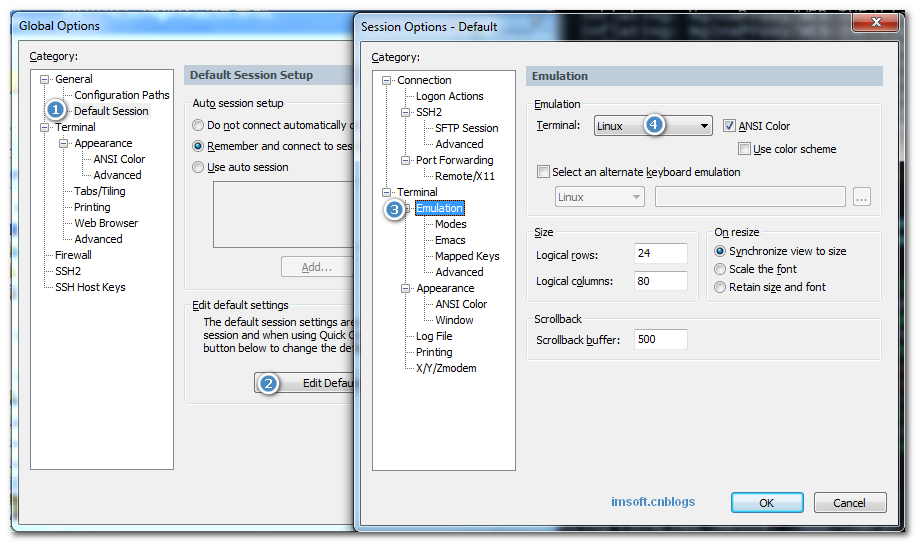
②选择自定义颜色
④将字体的颜色变浅,将背景的颜色变深
⑤再次勾选此选项,即可完成设置

在讨论这个问题前,我们先来了解一下物理端口、逻辑端口、端口号等计算机概念。
端口相关的概念:
在网络技术中,端口(Port)包括逻辑端口和物理端口两种类型。物理端口指的是物理存在的端口,如ADSL Modem、集线器、交换机、路由器上用 于连接其他网络设备的接口,如RJ-45端口、SC端口等等。逻辑端口是指逻辑意义上用于区分服务的端口,如TCP/IP协议中的服务端口,端口号的范围从0到65535,比如用于浏览网页服务的80端口,用于FTP服务的21端口等。由于物理端口和逻辑端口数量较多,为了对端口进行区分,将每个端口进行了编号,这就是端口号
端口按端口号可以分为3大类:
1:公认端口(Well Known Port)
公认端口号从0到1023,它们紧密绑定与一些常见服务,例如FTP服务使用端口21,你在 /etc/services 里面可以看到这种映射关系。
2:注册端口(Registered Ports):
从1024到49151。它们松散地绑定于一些服务。也就是说有许多服务绑定于这些端口,这些端口同样用于许多其它目的.
3: 动态或私有端口(Dynamic and/or Private Ports)
动态端口,即私人端口号(private port numbers),是可用于任意软件与任何其他的软件通信的端口数,使用因特网的传输控制协议,或用户传输协议。动态端口一般从49152到65535
Linux中有限定端口的使用范围,如果我要为我的程序预留某些端口,那么我需要控制这个端口范围。/proc/sys/net/ipv4/ip_local_port_range定义了本地TCP/UDP的端口范围,你可以在/etc/sysctl.conf里面定义net.ipv4.ip_local_port_range = 1024 65000
[root@localhost ~]# cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
[root@localhost ~]# echo 1024 65535 > /proc/sys/net/ipv4/ip_local_port_range
关于端口和服务,我曾经拿公共厕所打比方,公共厕所里的每一个厕所就好比系统的每一个端口,为人解决方便就是所谓的服务,你提供了这些服务,那么就必须开放端口(厕所),当有人上厕所时,就是在这些端口建立了链接。如果那个厕所被人占用了,就表示端口号被服务占用了,如果有一天这里不提供公共厕所服务了,这个公共厕所被拆除了,自然也就没有了端口号了。其实更形象的例子,就好比银行大堂,端口号是那些柜台,而那些取号办理业务的人就好比链接到服务器的各种客户端。他们通过端口重定向技术与柜台发送业务联系。再举一个通俗易懂的例子,端口号,好比高铁线上的每个站点,例如,长沙、岳阳等分别代表一个端口号,旅客通过火车票到各自的站点,就好比各个应用程序发往服务器端口的IP包。
端口与服务的关系
端口有什么用呢?我们知道,一台拥有IP地址的主机可以提供许多服务,比如Web服务、FTP服务、SMTP服务等,这些服务完全可以通过1个IP地址来实现。那么,主机是怎样区分不同的网络服务呢?显然不能只靠IP地址,因为IP 地址与网络服务的关系是一对多的关系。实际上是通过“IP地址+端口号”来区分不同的服务的。
端口号与相应服务的对应关系存放在/etc/services文件中,这个文件中可以找到大部分端口。
如何检查端口是否开放,其实不整理,还不知道有这么多方法!
1:nmap工具检测开放端口
nmap是一款网络扫描和主机检测的工具。nmap的安装非常简单,如下所示rpm安装所示。
[root@DB-Server Server]# rpm -ivh nmap-4.11-1.1.x86_64.rpm
warning: nmap-4.11-1.1.x86_64.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ########################################### [100%]
1:nmap ########################################### [100%]
[root@DB-Server Server]# rpm -ivh nmap-frontend-4.11-1.1.x86_64.rpm
warning: nmap-frontend-4.11-1.1.x86_64.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ########################################### [100%]
1:nmap-frontend ########################################### [100%]
[root@DB-Server Server]#
关于nmap的使用,都可以长篇大写特写,这里不做展开。如下所示,nmap 127.0.0.1 查看本机开放的端口,会扫描所有端口。 当然也可以扫描其它服务器端口。
[root@DB-Server Server]# nmap 127.0.0.1
Starting Nmap 4.11 ( http://www.insecure.org/nmap/ ) at 2016-06-22 15:46 CST
Interesting ports on localhost.localdomain (127.0.0.1):
Not shown: 1674 closed ports
PORT STATE SERVICE
22/tcp open ssh
25/tcp open smtp
111/tcp open rpcbind
631/tcp open ipp
1011/tcp open unknown
3306/tcp open mysql
Nmap finished: 1 IP address (1 host up) scanned in 0.089 seconds
You have new mail in /var/spool/mail/root
[root@DB-Server Server]#
2:netstat 工具检测开放端口
[root@DB-Server Server]# netstat -anlp | grep 3306
tcp 0 0 :::3306 :::* LISTEN 7358/mysqld
[root@DB-Server Server]# netstat -anlp | grep 22
tcp 0 0 :::22 :::* LISTEN 4020/sshd
tcp 0 52 ::ffff:192.168.42.128:22 ::ffff:192.168.42.1:43561 ESTABLISHED 6198/2
[root@DB-Server Server]#
如上所示,这个工具感觉没有nmap简洁明了。当然也确实没有nmap功能强大。
3:lsof 工具检测开放端口
[root@DB-Server Server]# service mysql start
Starting MySQL......[ OK ]
[root@DB-Server Server]# lsof -i:3306
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
mysqld 7860 mysql 15u IPv6 44714 TCP *:mysql (LISTEN)
[root@DB-Server Server]# service mysql stop
Shutting down MySQL..[ OK ]
[root@DB-Server Server]# lsof -i:3306
[root@DB-Server Server]#
[root@DB-Server Server]# lsof -i TCP| fgrep LISTEN
cupsd 3153 root 4u IPv4 9115 TCP localhost.localdomain:ipp (LISTEN)
portmap 3761 rpc 4u IPv4 10284 TCP *:sunrpc (LISTEN)
rpc.statd 3797 rpcuser 7u IPv4 10489 TCP *:1011 (LISTEN)
sshd 4020 root 3u IPv6 12791 TCP *:ssh (LISTEN)
sendmail 4042 root 4u IPv4 12876 TCP localhost.localdomain:smtp (LISTEN)
4: 使用telnet检测端口是否开放
服务器端口即使处于监听状态,但是防火墙iptables屏蔽了该端口,是无法通过该方法检测端口是否开放的。
5:netcat工具检测端口是否开放。
[root@DB-Server ~]# nc -vv 192.168.42.128 1521
Connection to 192.168.42.128 1521 port [tcp/ncube-lm] succeeded!
[root@DB-Server ~]# nc -z 192.168.42.128 1521; echo $?
Connection to 192.168.42.128 1521 port [tcp/ncube-lm] succeeded!
0
[root@DB-Server ~]# nc -vv 192.168.42.128 1433
nc: connect to 192.168.42.128 port 1433 (tcp) failed: No route to host
关闭端口和开放端口
关闭端口和开放端口应该是两种不同的概念,每个端口都有对应的服务,因此要关闭端口,只要关闭相应的服务就可以了。像下面例子,开启了MySQL服务,端口3306处于监听状态,关闭MySQL服务后,端口3306自然被关闭了
[root@DB-Server Server]# service mysql start
Starting MySQL......[ OK ]
[root@DB-Server Server]# lsof -i:3306
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
mysqld 7860 mysql 15u IPv6 44714 TCP *:mysql (LISTEN)
[root@DB-Server Server]# service mysql stop
Shutting down MySQL..[ OK ]
[root@DB-Server Server]# lsof -i:3306
[root@DB-Server Server]#
所以,系统里面有些不必要的端口和服务,从安全考虑或资源节省角度,都应该关闭那些不必要的服务。关闭对应的端口。另外,即使服务开启,但是防火墙对对应的端口进行了限制,这样端口也不能被访问,但端口本身并没有关闭,只是端口被屏蔽了。



{kind=link}
{kind=link}
{kind=link}